Logistic Functions
Numeric Representation![]()
|
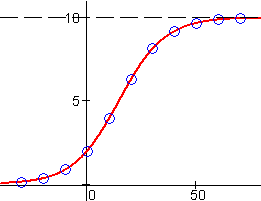
A quick inspection of the output values in the data table for g at right shows the typical pattern for logistic growth: Small initial rates which then accelerate up to a point of inflection, after which the growth slows down and eventually approaches a limiting value. We are fortunate to have a data set which displays the entire progress of a logistic function's For example, exponential growth displays a pattern of increase by constant multiples over equal input intervals. (See the section on numeric representations of exponential functions.) The early parts of the data for g show approximately this pattern:
|
In the early stages of logistic growth
Likewise, the latter part of logistic growth can be difficult to distinguish from bounded exponential growth. Near its limiting value, logistic growth
If we use

We use the similarities between logistic growth and exponential growth to find suitable values for the parameters a , b , and c in a logistic model
The parameter a , as we have noted, is just the data's limiting value. Unless the data displays the latter stages of logistic growth, and the limiting value is quite obvious (approximately 10 in the data set for g), it may take some trial and error to find a value for this parameter that will fit the data.
Values for the parameters b and c are found using properties of exponential functions.
In the early stages of growth, when the model behaves approximately like
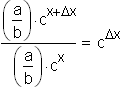
In the data set for g ,
Similarly, in the later stages of growth, when
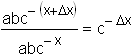
In the data set for g ,
Having found a and c, we can usually adjust b until the model fits the data. In this case, a value of
|
|
|
| Back to Contents | |
